
Telling op een helling
[ooO]
De familie Van der Torus is een heel normale, gemiddelde familie. Voor zover een familie van wiskundigen normaal kan zijn. Ze komen allerlei alledaagse problemen tegen. Kom je zelf uit een wiskundig gezin of ben je een (mogelijk toekomstige) wiskundige, dan kun je je ervaringen, vragen en ideeën delen met de familie Van der Torus via e-mail naar [email protected].
Milli en Mu hadden al wat nagedacht over het nieuwe probleem, dat vorige keer was voorgelegd. Daarbij gaat het om een tabel met getallen, waarbij elke rij en elke kolom oplopend gesorteerd is. De uitdaging is om een algoritme te ontwerpen dat het aantal voorkomens van een gegeven waarde, zeg X, in die tabel telt. Mu klaagde dat het probleem wel erg abstract was, want wanneer kom je dat probleem nou echt tegen? Daarom hadden ze nog geen code geschreven. Pi vraagt ze de volgende tabel te bekijken (de code bij dit artikel vind je, kopiëer- en plakbaar, onder de knop [Bekijk oplossing]):
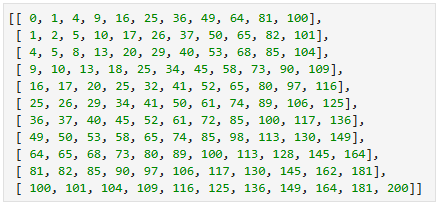
Voordat Pi kan uitleggen waartoe deze tabel dient, roepen Millie en Mu in koor: "sommen van twee kwadraten, dus ![]() ". Pi vervolgt met de vraag: " Hoe vaak komt $65$ voor?" Dat blijkt toch nog lastig in een oogopslag te tellen. Maar het antwoord laat niet lang op zich wachten: "4 keer". Daarop legt Pi uit dat je dit ook kan opvatten als de vraag hoeveel roosterpunten er liggen op de kwartcirkel (in het kwadrant rechtsboven) met de oorsprong als middelpunt en straal $\sqrt{65}$. Daar moet Mu nog even over denken, maar Milli fluistert "Pythagoras" en dan is het duidelijk. Dus met dat algoritme kun je bepalen op hoeveel manieren je een getal kan schrijven als som van twee kwadraten.
". Pi vervolgt met de vraag: " Hoe vaak komt $65$ voor?" Dat blijkt toch nog lastig in een oogopslag te tellen. Maar het antwoord laat niet lang op zich wachten: "4 keer". Daarop legt Pi uit dat je dit ook kan opvatten als de vraag hoeveel roosterpunten er liggen op de kwartcirkel (in het kwadrant rechtsboven) met de oorsprong als middelpunt en straal $\sqrt{65}$. Daar moet Mu nog even over denken, maar Milli fluistert "Pythagoras" en dan is het duidelijk. Dus met dat algoritme kun je bepalen op hoeveel manieren je een getal kan schrijven als som van twee kwadraten.
Oplossing
"Nou, hier is mijn Python code", zegt Mu, die meteen aan de slag is gegaan:

Milli heeft al meer ervaring met Python en laat zien dat het minder omslachtig kan:
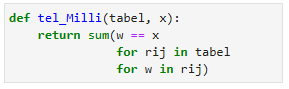
Dat werkt omdat in Python een booleaanse waarde, zoals het resultaat van ![]() , ook als getal gebruikt kan worden:
, ook als getal gebruikt kan worden: ![]() wordt omgezet in $0$ en
wordt omgezet in $0$ en ![]() in $1$. Deze nullen en enen worden door
in $1$. Deze nullen en enen worden door ![]() allemaal opgeteld, waarbij
allemaal opgeteld, waarbij ![]() de rijen van tabel doorloopt en
de rijen van tabel doorloopt en ![]() op zijn beurt de kolommen van
op zijn beurt de kolommen van ![]() doorloopt.
doorloopt.
Pi vindt beide oplossingen even goed, of eigenlijk, even slecht. Want bij een tabel van $M \times N$ kost het in de orde van $MN$ stappen. Met $M = N = 10^6$ duurt het dan wel erg lang. Daarop werpt Milli tegen dat die tabel dan ook niet meer in het geheugen past. Phi mengt zich nu ook in de discussie: "Die tabel is ook helemaal niet nodig, want als je een functie ![]() hebt om de waarde
hebt om de waarde ![]() te berekenen, dan is dat goed genoeg." Inderdaad kost een functiedefinitie meestal (veel) minder ruimte dan een tabel. Daarna vertaalt Phi de code van Milli:
te berekenen, dan is dat goed genoeg." Inderdaad kost een functiedefinitie meestal (veel) minder ruimte dan een tabel. Daarna vertaalt Phi de code van Milli:
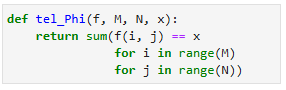
De functie ![]() telt hoe vaak functie $f$ de waarde $x$ aanneemt voor argumenten $(i, j)$ met $0 \le i \le M$ en $0 \le j \le N$. Als je toch een tabel hebt, dan kun je er als volgt een functie van maken:
telt hoe vaak functie $f$ de waarde $x$ aanneemt voor argumenten $(i, j)$ met $0 \le i \le M$ en $0 \le j \le N$. Als je toch een tabel hebt, dan kun je er als volgt een functie van maken: ![]() . Dit is de functie van argumenten
. Dit is de functie van argumenten ![]() met als waarde
met als waarde ![]() . Voor bovenstaande tabel gebruik je dan
. Voor bovenstaande tabel gebruik je dan ![]() als
als ![]() . Pi beaamt dat het nu dus zeker efficiënter moet.
. Pi beaamt dat het nu dus zeker efficiënter moet.
Milli en Mu vragen om een hint, want dit klinkt toch wat magisch. "Okay", zegt Pi, "jullie hebben nog geen gebruik gemaakt van het gegeven dat de tabel, per rij en per kolom, oplopend gesorteerd is. Hoe kun je dat gebruiken? Denk nog eens aan binair zoeken. Daarbij kun je op grond van één vergelijking meteen een aantal waarden uitsluiten." Pi tekent het volgende diagram en stelt dat we voor het gemak eerst kunnen aannemen dat rijen en kolommen geen dubbele waarden bevatten.
| $f$ | $j$ | ||||||
| ^ | |||||||
| ^ | |||||||
| ^ | |||||||
| $i$ | < | < | < | $f(i,j)$ | < | < | < |
| ^ | |||||||
| ^ | |||||||
| ^ |
Milli hapt toe: "Als $f(i, j) < x$ dan geldt ook $f(k, j) < x$ voor alle $k < i$ (in het oranje)." Mu vult meteen aan: "Als $x < f(i, j)$ dan geldt ook $x < f(i, \ell)$ voor alle $\ell > j $(in het lichtblauw)." Pi bevestigt dit en voegt nog toe: "Als $f(i, j) = x$ dan geldt ook $f(k, j) < x$ voor alle $k < i$ en bovendien $x < f(i, \ell)$ voor alle $\ell > j$, omdat we eerst aannemen dat $x$ in elke rij en elke kolom hooguit één keer voorkomt." Pi moedigt ze aan om dit te verwerken in een programma, met de hint om met handige waarden van $i, j$ te beginnen.
Die laatste hint roept wat discussie op. Mu vindt het vanzelfsprekend om linksboven met ![]() te beginnen. Waarop Milli opmerkt dat het diagram dan niet lekker werkt. En dat geldt voor rechtsonder ook. Het ziet ernaar uit dat linksonder een beter begin is, omdat volgens het diagram dan meteen een hele rij of hele kolom kan worden uitgesloten. Dit leidt tot het volgende verrassend eenvoudige programma, dat ze aan Pi opdragen:
te beginnen. Waarop Milli opmerkt dat het diagram dan niet lekker werkt. En dat geldt voor rechtsonder ook. Het ziet ernaar uit dat linksonder een beter begin is, omdat volgens het diagram dan meteen een hele rij of hele kolom kan worden uitgesloten. Dit leidt tot het volgende verrassend eenvoudige programma, dat ze aan Pi opdragen:

Het idee hierachter is dat het aantal voorkomens van $x$ in de rechthoek rechtsboven $(i, j)$ d.w.z. van $f(k, \ell)$ met $0 \le k \le i$ en $j \le \ell < N$, nog bij ![]() moet worden geteld. Met elke slag van de while-lus wordt de rechthoek een rij en/of kolom kleiner.
moet worden geteld. Met elke slag van de while-lus wordt de rechthoek een rij en/of kolom kleiner.
"Hoe efficiënt is dit programma?", vraagt Pi. Het antwoord hierop is niet zo moeilijk, aangezien in elke slag van de while-lus de waarde van $i - j$ met minstens één afneemt. De startwaarde is $M - 1$ en volgens de conditie van de while-lus eindigt de lus met $i = -1$ of $j = N$. Dus in het slechtste geval is de eindwaarde van $i - j = -N$ en daarmee het aantal slagen van de lus hooguit $M + N$. In zekere zin loopt dit algoritme zo goed mogelijk langs een hoogtelijn, waar de functie ongeveer gelijk aan $x$ is. Dat is heel wat beter dan de $MN$ stappen die ze eerst hadden. Nu is het een eitje om te bepalen op hoeveel manieren $10^{12}$ te schrijven is als som van twee kwadraten:
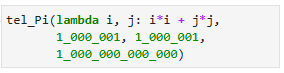
(Als je het wilt controleren: dat kan op 14 manieren.) Inderdaad werkt dit lekker voor sommen van kwadraten, omdat die functie strikt monotoon stijgt in beide argumenten. Pi wil nu terug naar het oorspronkelijke probleem, waarbij de rijen en kolommen niet-dalend zijn en er dus dubbele kunnen voorkomen. Dit is bijvoorbeeld het geval in de tabel met het naar beneden afgeronde meetkundige gemiddelde, ofwel de functie $mg(i,j) = \left\lfloor\sqrt{ij}\right\rfloor$ . Hier is die tabel voor $1 \le i, j \le 9$:

Hoe vaak staat in bovenstaande tabel de waarde 5? Het algoritme ![]() is nu niet van toepassing. Phi probeert te helpen door in herinnering te brengen dat de formule $2\pi r$ voor de omtrek van een cirkel te verkrijgen is door de formule $\pi r^2$ voor de oppervlakte van die cirkel te differentiëren naar $r$. Ofwel de omtrek krijg je door twee bijna even grote cirkels te nemen met stralen $r$ en $r + h$ en dan het verschil in oppervlaktes te beschouwen. Dit is een ring met breedte $h$. Je krijgt derhalve de omtrek als je de oppervlakte van die ring door $h$ deelt, mits $h$ klein is. Als $h$ naar nul gaat is dat precies de definitie van afgeleide. Mu zegt dit weinig, maar bij Milli gaat er een lichtje branden: "Wat als we alle waardes ${}\le x$ tellen en daar alle waardes ${}< x$ van aftrekken?" Dat vindt Phi een geweldig idee. Bovendien geldt voor gehele getallen dat het aantal ${}< x$ gelijk is aan het aantal ${}\le x - 1$. Je hoeft dus maar één nieuw algoritme te ontwerpen dat het aantal waardes ${}\le x$ telt.
is nu niet van toepassing. Phi probeert te helpen door in herinnering te brengen dat de formule $2\pi r$ voor de omtrek van een cirkel te verkrijgen is door de formule $\pi r^2$ voor de oppervlakte van die cirkel te differentiëren naar $r$. Ofwel de omtrek krijg je door twee bijna even grote cirkels te nemen met stralen $r$ en $r + h$ en dan het verschil in oppervlaktes te beschouwen. Dit is een ring met breedte $h$. Je krijgt derhalve de omtrek als je de oppervlakte van die ring door $h$ deelt, mits $h$ klein is. Als $h$ naar nul gaat is dat precies de definitie van afgeleide. Mu zegt dit weinig, maar bij Milli gaat er een lichtje branden: "Wat als we alle waardes ${}\le x$ tellen en daar alle waardes ${}< x$ van aftrekken?" Dat vindt Phi een geweldig idee. Bovendien geldt voor gehele getallen dat het aantal ${}< x$ gelijk is aan het aantal ${}\le x - 1$. Je hoeft dus maar één nieuw algoritme te ontwerpen dat het aantal waardes ${}\le x$ telt.
Daarmee gaan Milli en Mu aan de slag. Ze redeneren als volgt. Als $f(i, j) \le x$ dan geldt $f(k, j) \le x$ voor $k \le i$. Dit betreft $i + 1$ waarden, namelijk $f(0, j)$ tot en met $f(i, j)$. En als $x < f(i, j)$ dan geldt $x < f(i, \ell)$ voor $\ell ≥ j$. Hier is hun resulterende code, die er nog eenvoudiger uitziet dan wat ze al hadden:

Aangezien we zowel alle waardes ${}\le x$ als alle waardes ${}< x$ willen tellen, zodat we die van elkaar af kunnen trekken, moeten we de functie twee keer gebruiken. Maar dat verdubbelt het aantal stappen hooguit. Overigens, als je weet dat de functie symmetrisch is, d.w.z. dat $f(i, j) = f(j, i)$, dan kun je doorgaan tot $i = j$ geldt (je moet nog wel even oppassen dat je de diagonaal niet dubbel telt of vergeet). Dat scheelt weer de helft in het aantal stappen.
Ditzelfde idee is te gebruiken om het probleem van de beroemdheid op te lossen. Er zijn $N$ personen op een festival. Precies één daarvan is een beroemdheid, d.w.z. iedereen kent deze beroemdheid en de beroemdheid zelf kent niemand. Gegeven is een booleaanse functie (of tabel) $kent(i, j)$ die aangeeft of persoon $i$ persoon $j$ kent $(0 \le i, j < N)$. Ontwerp een algoritme dat efficiënt de beroemdheid vindt. Een oplossing staat op de website.
Volgende keer
Milli en Mu spelen elke dag een breinbreker op hun telefoon en verzamelen daarvoor punten. Soms is dat aantal punten negatief, omdat ze vergeten zijn te spelen of fouten maakten. Hier is een mogelijke reeks scores:
![]()
Ontwerp een (efficiënt) algoritme dat de beste streak bepaalt: een aaneengesloten periode van dagen met de hoogste totaalscore. Door de negatieve scores is dat nog niet zo makkelijk.
Bekijk oplossing