
Ga jij je examens halen?
[ooO]
Eindexamenjaar: nog een paar keer knallen en dan heb je je diploma binnen. Natuurlijk weet je al dat het goed gaat komen, maar toch bereken je nog maar een keer wat je minimaal moet halen voor het centraal examen. Maar wat is de kans dat je ook echt hoog genoeg gaat halen voor het centraal examen? Hoe kan je wiskunde gebruiken om deze kans te bepalen?
Om maar gelijk met de deur in huis te vallen: deze kans exact berekenen, lukt niet. Daarvoor moet je namelijk heel veel extra informatie hebben, die je niet altijd hebt. Je krijgt bijvoorbeeld niet van tevoren de examenopgaven te zien. Natuurlijk, je kan wel oude examens maken en op die manier een schatting maken, maar oude examens maak je veel meer op je gemak dan een echt examen. Je zal waarschijnlijk geen examenstress hebben wanneer je een oud examen aan het oefenen bent.
Een manier om de kans te schatten, is door het gebruik van cijfers van examenkandidaten van vorig jaar. Gelukkig heb je van een aantal bekenden hun examencijfers van vorig jaar kunnen krijgen, zie tabel 1. Omdat we alleen maar willen weten of iemand hoog genoeg heeft gescoord voor het centraal examen (CE), voegen we een extra kolom toe waar we een 1 invullen als het cijfer voor het centraal examen inderdaad hoog genoeg was om samen met het schoolexamencijfer (SE) gemiddeld op 5,5 of hoger uit te komen.
| gemiddelde SE |
cijfer CE |
hoog genoeg voor CE? |
| $7{,}1$ | $6{,}4$ | $1$ |
| $5{,}3$ | $4{,}9$ | $0$ |
| $5{,}8$ | $6{,}1$ | |
| $6{,}0$ | $7{,}2$ | |
| $5{,}6$ | $5{,}1$ | |
| $6{,}0$ | $4{,}8$ | |
| $7{,}2$ | $7{,}5$ | |
| $5{,}3$ | $6{,}0$ | |
| $6{,}2$ | $6{,}0$ | |
| $8{,}8$ | $9{,}1$ | |
| $5{,}0$ | $5{,}2$ | |
| $4{,}5$ | $5{,}7$ |
Opgave 1Maak de laatste kolom in tabel 1 af. |
Hoe kunnen we dit gebruiken om de kans te schatten dat je cijfer hoog genoeg zal zijn voor het centraal examen? We gaan op zoek naar een wiskundig model dat bij de $x$-variabele, het gemiddelde cijfer voor het schoolexamen, een schatting geeft van de $y$-variabele, de kans dat je een hoog genoeg cijfer voor je CE haalt. In figuur 1 zie je hoe dat eruit zou kunnen zien: een plot van de datapunten uit tabel 1 met functie $f(x)$.
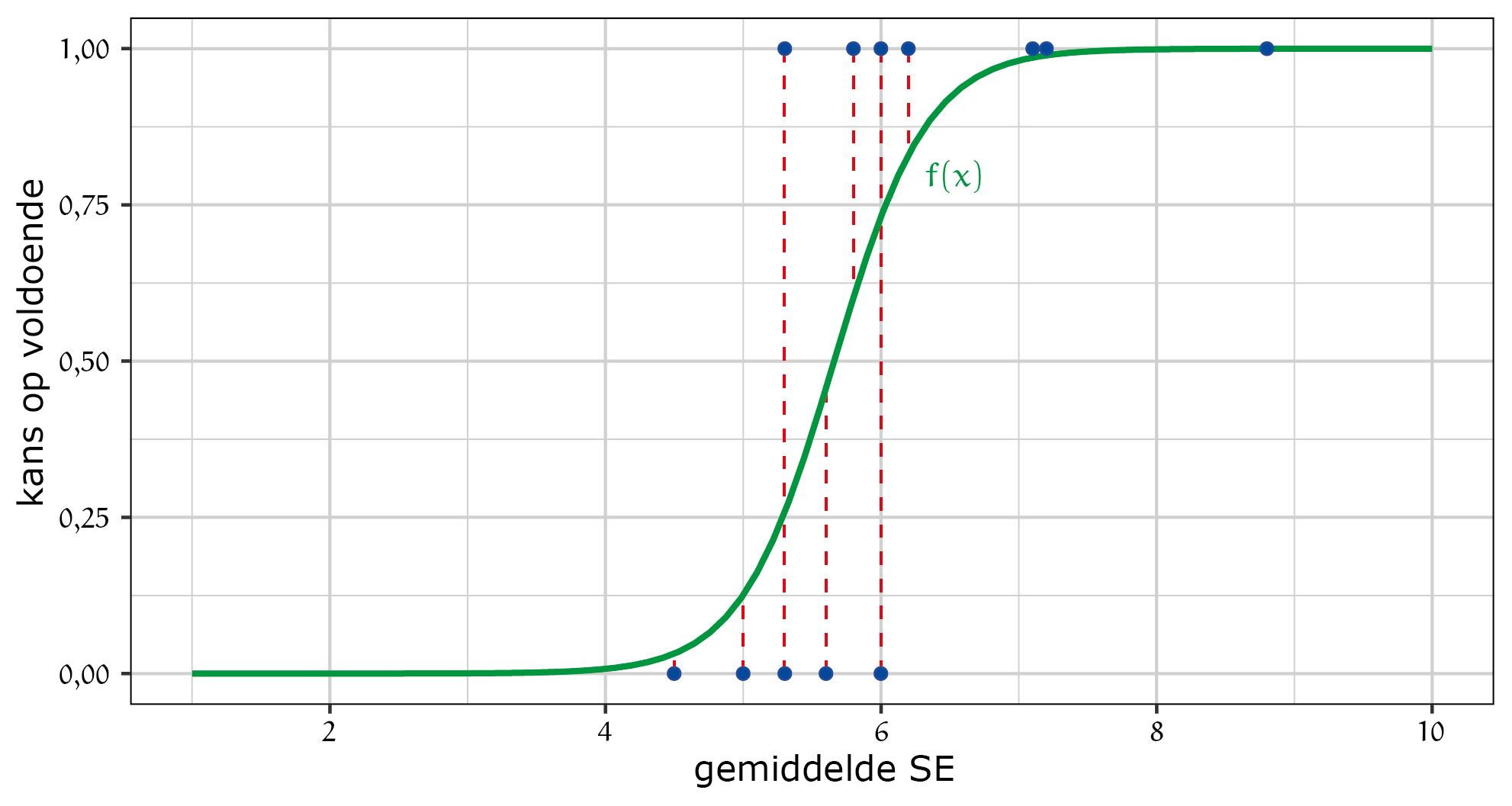
Het wiskundig model moet op een bepaalde manier goed bij de datapunten passen. Daar zijn veel verschillende functies voor te bedenken. De functie die in figuur 1 in groen geplot is is een functie die in de praktijk veel gebruikt wordt. Het is de logistische functie, die als formule heeft:
$$f(x)=\frac{1}{1+{\rm e}^{-(ax+b)}}.$$
De waarde van $f(x)$ kan dan opgevat worden als de kans dat je uiteindelijk een voldoende staat voor wiskunde als je gemiddelde schoolexamencijfer $x$ is.
Opgave 2Hoe zie je aan de formule van $f(x)$ dat deze functie nooit lager dan $0$ en ook nooit hoger dan $1$ kan worden? |
In de logistische functie zie je twee parameters, $a$ en $b$. De vraag is nu hoe we deze parameters moeten invullen. We willen dat de logistische functie zo goed mogelijk aansluit op de datapunten, dus kunnen we per datapunt kijken hoe ver $f(x)$ afwijkt van de y-waarde die het had moeten zijn. In figuur 1 is dat weergegeven met de rode gestreepte verticale lijnstukken.
Elk van deze lijnstukken geven we een waarde, die de fout moet voorstellen. Daarbij moeten we rekening houden met de vorm van de logistische functie. Omdat de logistische functie van $0$ tot $1$ loopt, zou de grootst mogelijke fout $1$ zijn. Maar eigenlijk zouden we de grootst mogelijke fout veel zwaarder mee willen laten wegen bij het bepalen van $a$ en $b$. Dat kan door slim gebruik te maken van de logaritme. Stel dat voor een datapunt $y = 1$ geldt, dan definëren we de bijbehorende fout als $-\ln(f(x))$. Op een soortgelijke wijze is de fout voor een datapunt met $y = 0$ gelijk aan $-\ln(1 - f(x))$.
Opgave 3Leg uit waarom voor een willekeurig datapunt de bijbehorende fout berekend kan worden met $$-y\cdot\ln(f(x))-(1-y)\cdot\ln(1-f(x)).$$ |
Voor elk van de lijnstukken kunnen we de bijbehorende fout berekenen en de resultaten bij elkaar optellen. De uitkomst willen we zo laag mogelijk krijgen, want dan is er kennelijk niet veel verschil tussen $f(x)$ en $y$. De uitkomst van de optelsom is een functie met variabelen $a$ en $b$. Deze functie noemen we ook wel de loss functie $L(a, b)$.
Om de loss functie te minimaliseren, moeten we deze eerst differentiëren naar $a$ en ook differentiëren naar $b$ en vervolgens beide afgeleiden gelijk stellen aan nul en dit oplossen voor $a$ en $b$. Om een indruk te geven: de loss functie bij de eerste twee regels van tabel 1 is:
$$L(a,b)=-\ln\left(\frac{1}{1+{\rm e}^{-(7{,}1a+b)}}\right) - \ln\left(1-\frac{1}{1+{\rm e}^{-(5{,}3a+b)}} \right).$$
Je kan je waarschijnlijk wel voorstellen dat dit differentiëren geen pretje is. En dan hebben we hier alleen nog maar de loss functie voor twee datapunten opgesteld!
Om die reden laten we in de praktijk al het rekenwerk over aan de computer. Een van de vele websites die dit voor je kunnen doen is https://stats.blue/Stats_Suite/logistic_regression_calculator.html. Maar wil je weten hoe je die berekeningen ook zelf kan uitvoeren op de computer? Klik dan hieronder op de knop [Bekijk oplossing]. Als we de gegevens van tabel 1 invullen en de loss functie minimaliseren krijgen we als oplossing $a \approx 2{,}942$ en $b \approx -16{,}65$, waarmee we komen tot de logistische functie
$$f(x)=\frac{1}{1+{\rm e}^{-(2{,}942x-16{,}55)}}.$$
Dat is ook de functie waarvan de grafiek in figuur 1 geplot is. Aan figuur 1 kan je al zien dat de kans op een voldoende voor wiskunde kleiner is dan $50\%$ als je schoolexamengemiddelde een $5{,}5$ is. Maar met de formule kan je ook precies berekenen vanaf welk schoolexamengemiddelde die kans minstens $50\%$ is, gebaseerd op de data uit tabel 1.
Opgave 4Bereken bij welk schoolexamengemiddelde de kans op een voldoende minstens $0{,}5$ is. |
De hierboven besproken techniek, waarin we een logistische functie zo passend mogelijk proberen te maken op een dataset, heet logistische regressie. Deze techniek komt uit de statistiek en is daarnaast ook een opstapje naar het domein van de data science en AI, het domein van de slimme algoritmes waar je vandaag de dag niet aan ontkomt. Slimme algoritmes die allemaal, net als logistische regressie, ook gebaseerd zijn op wiskunde en statistiek. En ook in de toekomst zal er nog meer dan genoeg zijn waar je wiskunde op kunt toepassen. Maar, één ding tegelijk, eerst maar je examens halen. Heel veel succes!
|
Sanjay Ramawadh is docent Toegepaste Wiskunde aan de Haagse Hogeschool. Bij de opleiding Toegepaste Wiskunde leer je op een wiskundige manier naar vraagstukken te kijken. De wiskundige kennis en vaardigheden die je op de middelbare school hebt geleerd, worden flink uitgebreid. Verder leer je hoe je het aangeleerde kunt toepassen in verschillende domeinen zoals de logistiek en techniek. Afhankelijk van de Hogeschool waar je de opleiding volgt is er naast wiskundevakken als calculus en lineaire algebra aandacht voor statistiek, kansberekening, operations research, data science en artificial intelligence. Gedurende de hele opleiding werk je naast de theorievakken aan projecten waarin je het geleerde direct in de praktijk brengt en word je getraind in professionele vaardigheden als presenteren en projectmatig werken. Van de vier jaar die de opleiding duurt loop je ongeveer een jaar stage buiten school. Je kunt de opleiding op vijf HBO's volgen: bij Fontys in Eindhoven, de Haagse Hogeschool in Delft, bij de Hogeschool van Amsterdam en InHolland in Amsterdam en bij NHL Stenden in Leeuwarden. |
||||
Bekijk oplossing